



A set of 275 non-redundant protein structures were derived from the
Brookhaven database. The non-redundancy is based on sequence rather
than structure so some structures from the same family appear in the
set. The structures were examined by Dr R. B. Russell (per. comm.)
and subjectively split into
domains using knowledge of protein folds and on the basis that
domains are globular units which are distinct from the rest of the
structure.
For proteins in this set which contained more than one
domain, the literature was searched for domain definitions in the
original publications that described the crystal structure.
This set is referred to as the reference set
as shown in Table 1. Table 1 also shows which definitions were
derived from the literature (identified by a 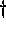 after the name).
after the name).
It was not possible to produce DSSP [Kabsch & Sander, 1983] files for 40 of the structures. CONTACTS could not be run on a further 4 structures as it requires all atoms to be present in the file. DOMAK, in its current form, has not been designed to deal with structures in which domains are made up of more than one chain. Therefore, kallikrein A was excluded from the set. However, it is conceptually simple to extend DOMAK to handle this case. The final set of protein structures analysed was 230. DOMAK required 16.5 hours of CPU to complete the analysis on this set, giving an average time of 4.3 minutes per protein. Calculation of contacts requires less than 2 minutes for the largest proteins (glycogen phosphorylase, 823 residues, took 101 seconds) and just over a second for the smaller ones (metallothionein isoform II, 62 residues; 1 second).