TARO Development Goals (requirements)
- Provide the user interface to execute arbitrary number of analyses against sequence(s) or sequence alignment and flexibly display the results according to the analyses performed. Make sure that the results of the current run can be used as input for the next analyses.(?) Keep the analyses history. Allow raw results to be obtained.
Current situation – TARO pipeline requires significant modifications to be able to run arbitrary number of analyses and display their results. - Speed up the calculations, and produce the feed back to the users as soon as the calculation is completed.
Current situation – currently TARO cluster submission engine does monitor the exit status of the programme. It checks the output to ensure that the results are calculated, however, some analyses naturally produce no output. This lead the tool to think that there was a problem with execution and it resubmits the job 3 times to the cluster. Number 3 is hardcoded in the code. No execution statistics is kept, e.g. failure rate, calculation time, making it impossible to learn and adjust program behaviour from the execution history. Calculation completion and availability of results are separated in TARO, some results appears a little earlier than others, but still later than they were calculated. This is not an issue for current TARO display, but could be an issue if more flexibility is given to the user in respect of different analysis execution. - Be portable, and easy to install elsewhere, free from dependencies of the particular execution environment (e.g. cluster or disk structure).
Current situation – TARO needs a major effort to make it less dependent on the execution environment; even this will not make it fully portable, an implementation in a platform independent language is needed. - Make use of external resources to perform calculations whenever possible e.g. EBI and NCBI web services. Provide for smarter job management by analyzing statistics of previous executions. This brings the benefits of better cluster resources use and improved speed of the calculations as well as contributes towards the stability and reliability of the services.
Current situation- this is not implemented in TARO - Provide the tools (possibly with API) for sending jobs to the cluster programmatically. The tools should include the job submission module which oversees the job execution, ensures the results are prepared by resubmitting the job in case of failure. Keep the statistics of execution times, failure rate and resources consumed to enable the tool to choose the service dynamically. This also relates to point 2.
Current situation – There are Perl tools for sending jobs to the cluster and some people within the group use them. However, there are room for improvements in this code too. (see section 2 for more info) Also, as far as I know there is no documentation for these tools. - Integrate TARO with PIMS
Can be done as discussed below in this document.
Current situation – However, if it is done that way, there is likely to be complications with a large number of requests coming from the PIMS, and inability of TARO to manage them. Ideally, the cluster submission module should manage the load on the cluster. - Provide a summary views on the data
- Obtain DNA sequencing of the protein for some analyses( which ones?)
- Update phyla file
PIMS TARO integration
- PIMS will provide a link to run a TarO query per target in PIMS. This link will be located on the target view in PIMS.
- TarO & PIMS will share one symmetric key that they will use for authentication and encryption purposes.
- Once the link in PIMS is clicked, PIMS will send a target sequence to TarO with parameters as follows: - pims= (IP address of the system, port number and context path) this information will be sufficient to uniquely identify the PIMS installation - user= PIMS user - target = PIMS target name (unique per PIMS target) - notify= the URL where TarO should POST the information to enable PIMS to display a link to the result
- The link in PIMS that submits a job to TarO will also open a page (from TarO) that gives the TarO query submitted information (or submission not successful message), including a query completion time estimate (see point 8).
- TarO will POST encrypted information to PIMS including both a URL for the relevant results page in TarO, as well as the PIMS "target" identifier. This URL will be sent by POST to the "notify" URL supplied in the PIMS request – and will replace the PIMS link for task submission.
- Given the parameters supplied by PIMS (from point 3) TarO will be able to identify that the request came from PIMS, to allow the TarO pipeline to be started safely.
- There will be a single TarO username for all PIMS installations.
- An estimate of the time TarO will take to return results will be calculated by TarO. This will be estimated from the number of queued TarO jobs at the time that the query is submitted.
- PIMS usage of TarO will need to be restricted as there are hundreds of targets that PIMS could submit to TarO at any given time.
- TarO will restrict the number of concurrent PIMS jobs to no more than two using a cluster token (pending discussion with Tom Walsh). Aside: There are an estimated ten PIMS installations at the moment, however PIMS could be downloaded and installed for personal use on ordinary laptop by anyone. In practice, due to the current complexity of installation this is unlikely to generate large numbers of additional users. Nevertheless this is a good reason to avoid having a cluster token per PIMS installation – it seems best to have single cluster token for all PIMS installations.
- Each PIMS instance will limit the number of targets (we suggest 5 per PIMS user) sent to TarO in any given day.
What we have (current TARO architecture)
TARO requires further development to meet the new development goals. Currently TARO execution flow is predefined and cannot be configured. Main steps of the execution are:- Finds the number of similar to the query proteins and run the number of analyses against all these proteins.
- Uploads the execution results in the database for presentation layer to display.
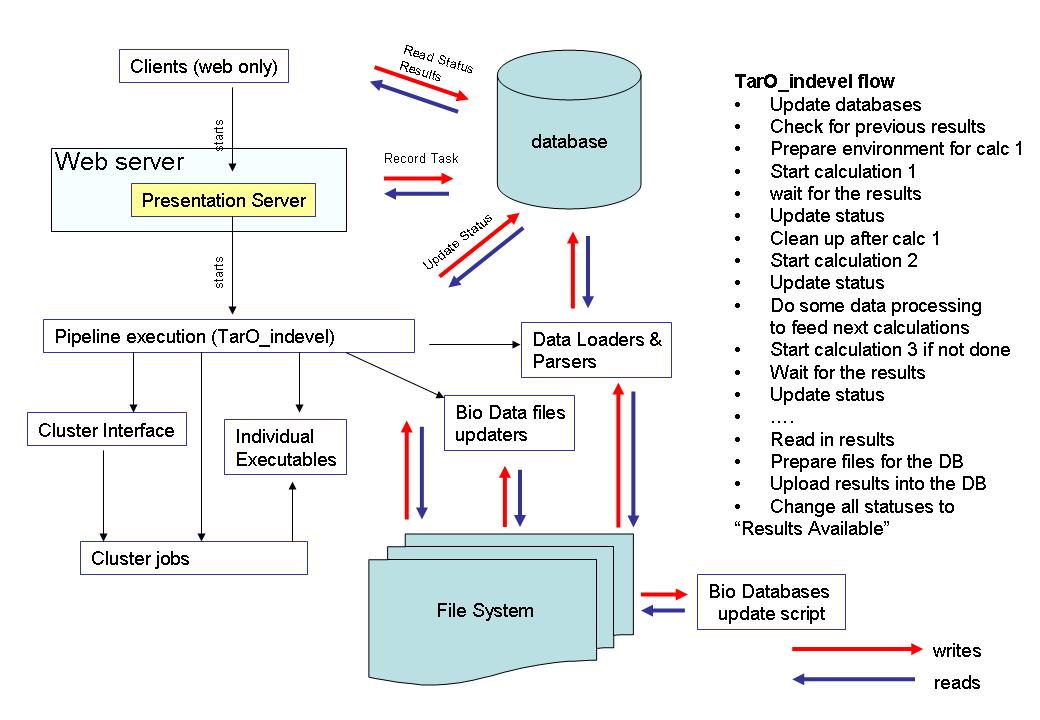
Suggested improvements (architecture that satisfy new requirements)
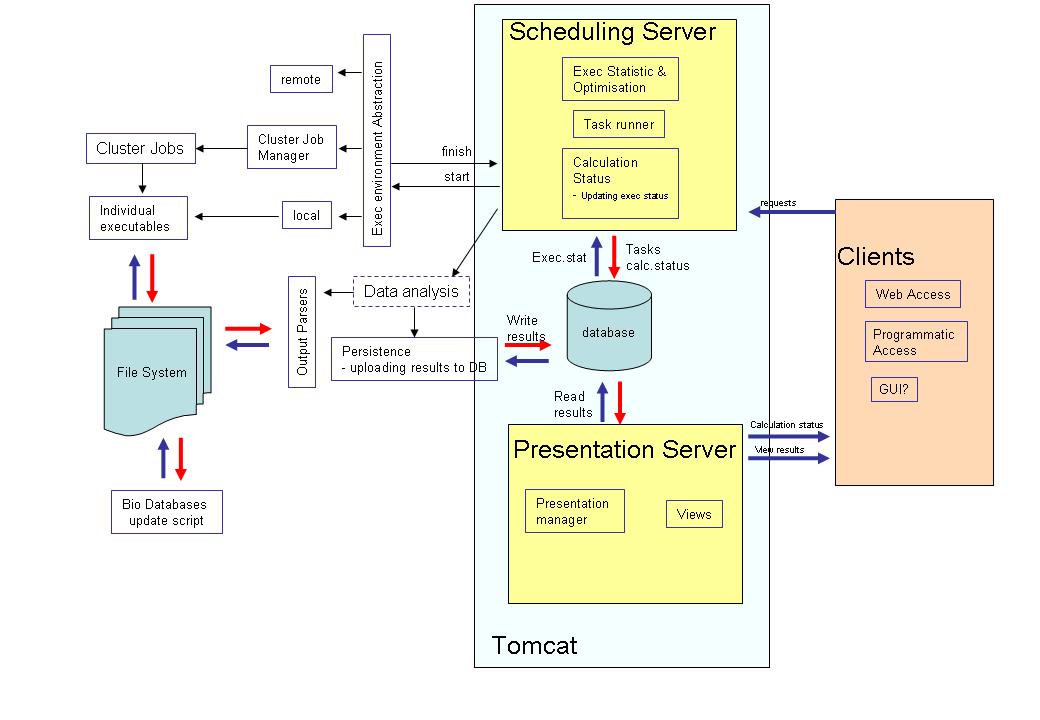
TARO aspects that meet the new requirements (no improvements needed)
TARO has a good architecture for data storage that is:
- All the calculation and data processing results are stored in two main directories under the subdirectory named by the query identifier making it relatively easy to locate the data of any query, only minor reorganization is needed to further simplify this.
- Many TARO external executables are mostly located in one directory; however some efforts needs to be spent to ensure the remaining executables are there too. This helps to manage TARO external dependencies.
- Pre-processed results required for the end-user are stored in relational database which greatly improves the consistency of the data, the performance of the presentation layer and unties the presentation from the execution logic completely
- Execution of the scripts is independent of the presentation, so it does not matter what happened in the background, users will always see the consistent picture.
- TARO database is well indexed and cope with the increasing amount of data well. Requires only minor attention mostly to improve consistency and reduce data redundancy.
- Database is well constrained to ensure the consistency of the data
- Presentation related scripts are all in one place and are not tied with the other scripts.
Suggested Improvements
- Introduce separation of logic, e.g. the database queries and updates can be done from the scripts dedicated to doing this and removed from any other scripts. The separation of responsibilities simplifies the code change and decreases the probability that the code change in one module breaking the other. Current situiation - there is some separation in TARO but much more have to be done to make it flexible. Database updates is especially worring.
- Libraries are the reusable components and thus should not rely on a particular execution environment e.g. make database queries. Extracting the database queries from them eliminate their dependency on the execution environment.
- Made results available to the users as soon as they have been calculated. - This is more important if a degree of flexibility is introduced in TARO analysis pipeline.
- It is preferable to have separate classes to perform different calculations, which would enable developing of a user customizable version of the pipeline. Modularisation also makes the system more flexible and amenable to the change.
Current situations - TARO goes some way towards this goal but there is more to be done to separate and clarify what different functions aims to achive. - Extract all hard coded paths (at the moment there are about 400 hard coded paths anywhere in TARO, 160 calls to system functions, among them are: cp, rm, mkdir, gzip etc) into one file or class to make it possible to change execution environment to enable the development of a separate downloadable version of TARO which can be deployed elsewhere.
- Remove as much as possible of the file and directory management, abstract the rest in one class. The file management done using operation system functions introduce dependency on the particular execution environment and is not safe, thus should be avoided. This can be achieved by preparation of an executable environment in one place, creating the directory structure up front and then using it later.
- Encapsulate cluster environment settings for different tasks into a separate class, monitor the execution closely. This will help to use the cluster optimally, localize and deal with failures, enable prioritization of the tasks.
- Provide two methods for obtaining database connection, one for read only purposes, another for reading and writing to centralized database to make database updates more explicit. Replace 44 getConnection statements with hard coded database URL, user & password with one getConnection method which is initialised from the properties file as well as 15 copies of sub executeSQL().
- Use one implementation of CreateLink(s), FormatDispText & FormatDispNum<X> throught (currently ~15 copies of each of these function exist).
Issues with TARO development & refactoring
- Functions lack parameter documentation and their expectations are unclear; often functions require a lot of parameters to come in. So individual functions are not easy to test and use.
- There is Cut & Paste style programming in CGI and data uploader scripts, leading to data & function redundancy where the same function or peace of code can be found in many scripts. There is also some data and function redundency in the core TARO scripts e.g. 9 methods to read fasta files (5 in taro_indevel.pl, 2 Pacrys.pm, 1 OB.pm, 1 Blast_Pars.pm).
- Perl is less suitable for complex projects see Perl deficiencies
- Lack of function tests make refactoring dangerous, as it is easy to brake things without noticing. TARO pipeline is a large script so to test it one needs to modularise it first. Any error made anywhere in the large script make the whole script to stop.
- Taking TARO code from the production environment and putting it back in is a manual procedure which require code modification and thus is not trivial. This is due to the hardcoded database connection and paths (e.g. references to modules, binaries, some scripts ).
- Lack of centralized configuration information leads to errors and introduces the possibility of breaking the system without noticing. (a small change in code lead to Pacrys calculation routine been broken for about two weeks)
Conclusion
New requirements require a change in TARO execution flow, a new abstraction layer which would help to make TARO more portable and less dependant on the environment, a better cluster job monitoring and a submission module and a new execution controller module. While it is relatively easy to add new analisys in established TARO workflow, or even remove some, it is much harder to change the flow itself. Thus enabling users to choose which analyses to run requires a significant change to TARO. Not only the main script would have to be changed but also a rethink of the presentation of the results will be needed, as it does not make sense to display empty fields for the calculation user did not perform.
Before the TARO code can be successfully refactored some test cases have to be created to ensure the TARO is still function properly when refactored. Given difficulties with code execution, lack of modularity, and the size and complexity of the project, the best way to go forward is to rewrite TARO using modular development approach in object oriented language. (also see deficiencies of Perl language)
If we reduce the requirements to simply integrate TARO with PIMS then, this can be achieved with little code change on TARO side. However, if done properly, the request scheduler, which balance the load requests from PIMS should be introduced.
How long it takes to implement the improvements and lay the foundation for the new features?
To my mind implementing all improvements listed above and the new functionality takes longer to achieve in Perl and the result may be of lesser quality, comparing with writing it from scratch in more flexible way in Java. If we going to significantly invest in this project, then i think the only option is a rewrite. Maintenance of Perl code gets much harder with the increase in size and complexity of the project. The time estimates shown below is for implementing from scratch option.
- Complete the design of the overall scheme - 1 week
- Job submission engine - 2 weeks
- Analysis pipeline - 3 days for 1 analysis. (~10 weeks)
- Data processing (e.g. parsing & merging BLAST output) need further investigation.
- Load data from prepared data files 1 week.
- Rewrite UI level with reusable components and in current technologies - 4 weeks.
Perl deficiencies (to my knowledge)
- Code is not self documentary and hard to comprehend. Even in object oriented style programming all the class members are stored in hash like structures, so unlimited number of fields can be added. At the same it is not clear what actually requires for the code to be executed.
- Not clear what arguments are required to the function, to devise this one need to study the code on the function being called.
- Cannot function as a black box (only on the script level, but not a method or class), the reason is above.
- Although it is said that object oriented programming is possible in Perl, but Perl does not encourage object oriented programming.
- In fact, lack of IDE and code parsers make it harder to do an object oriented programming in Perl. Object oriented programming lead to a large number of small classes and functions, one need to remember their name as there is no content assist in any Perl editor.
- So it is in fact easier in Perl to write one large programme. But then with the complexity of the script make it very difficult to implement any new requirements, especially those which do not fit very well in the established programme flow. Instead of one large script, object oriented approach would have led to the number of small concise, isolated functions, which is much easier to combine in the new ways. Not to mention to test.
- The above makes it much harder to develop a complex system in Perl than in any truly object oriented language like Java.
- A problem of any complexity can be solved if it is subdivided to a number of smaller problems. Object oriented approach greatly helps to divide a problem appropriately.
- Perl code has very weak integrity and it is impossible to enforce it.
- Lack of decent IDE slows down refactoring and development. Little hope that good IDE will ever be developed.