



Table 1 shows definitions of the domains found by the program DOMAK with default parameters. The Table also illustrates the corresponding reference definitions obtained from the literature and visual inspection (see Materials and Methods). In the following discussion the set of definitions obtained by the algorithm are referred to as the derived set.
For 161 of the proteins (Set A), the derived domains agree with those in the reference set (see Materials and Methods section for definition of reference set). This gives a confidence level of 70% for the method. Only 28 proteins (12%) (Set C) had all domains defined differently to the reference set.
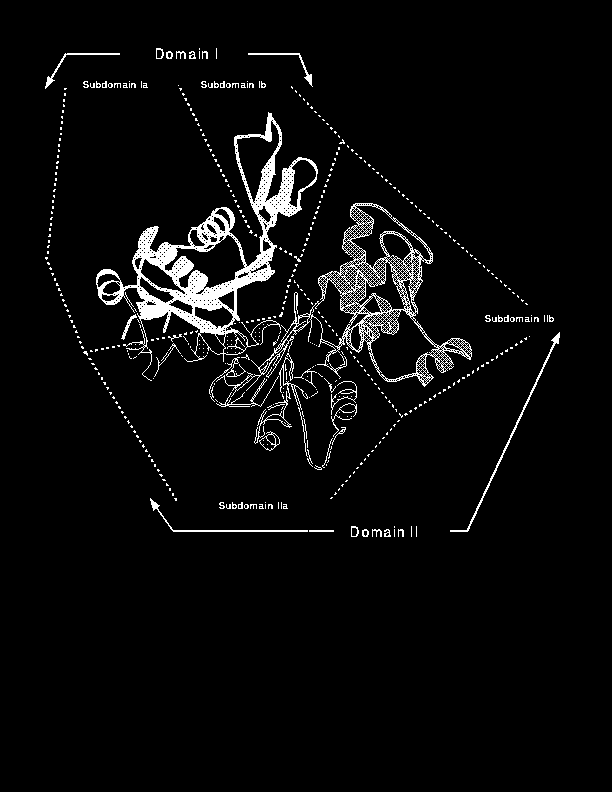
Domain definitions for 41 proteins (18%) (Set B) did not agree closely with the reference domains but either had one or more identically defined domain, or by inspection were split into what one would subjectively term domains. The 41 proteins in Set B highlight some of the difficulties with subjective definitions of domains. For example, glycogen phosphorylase is split into two domains. However, 18 residues at the C terminus come back across the N terminal domain. As the tail packs loosely against the first domain, the reference definitions do not assign it as part of either domain. However, DOMAK assigns it to the C terminal domain. A further example is actin which the authors of the structure classed as having two domains [Kabsch et al., 1990]. The first domain consists of residues 1-144 and 338-375 (domain I in Figure 2) and the second domain of residues 145-337 (domain II in Figure 2). However, it has also been suggested that each of the domains can be divided into two subdomains [Kabsch et al., 1990]. So residues 1-32, 70-144 and 338-375 make up subdomain Ia, while residues 33-69 make up subdomain Ib. For the second domain, residues 145-180 and 270-337 make up subdomain IIa and residues 181-269 make up subdomain IIb. DOMAK classes the protein into three domains, I, IIa, IIb with the default parameter values. If the default parameters are varied it is possible to find all four subdomains or find only the two main domains. Thus, there is a `grey area' of domain definition where one is not sure if a sub-unit of the protein structure should be classed as a separate domain or whether it is merely a lobe or local compact region. By choosing a set of parameters (principally the MSV value), a fixed subjective limit has been set and applied objectively to the whole set.
After applying the three reliability screens described in Materials and Methods, domains from 57 proteins are found that are believed to be incorrectly defined by the algorithm. 23 of the 57 proteins were incorrectly defined in comparison with the reference set. 25 were from Set B. 9 definitions from Set A were picked out as incorrect.
Hence, the list of definitions automatically defined as correct is
reduced to 173 (75% of the original 230 proteins). Of these
88% match the reference set. 9% are from Set B and split the
chain into what look like domains (Table 2). If one chooses to accept
these definitions the reliability of the algorithm rises to 97%. The
5 (3%) remaining structures that were incorrectly defined are listed in
Table 3, together with the reasons why the algorithm gave different
definitions with the default parameters.
The structures that are automatically defined as correct
are labelled with a ` ', in column A of Table 1.
', in column A of Table 1.
{kind=link}