



The concept at the centre of the domain identification algorithm is that residues comprising a domain make more contacts between themselves (internal contacts), than they do to the rest of the protein (external contacts). This follows from the work of Rossmann and Liljas (1974) who suggested that a domain has many short residue-residue distances within itself, but few short distances between it and the rest of the protein. Thus the ratio of the number of internal contacts to the number of external contacts should be large for a domain. Two residues are defined to make a contact if a heavy atom in one residue is within 5 Å of a heavy atom in the other.
If the protein is split into two arbitrarily chosen parts, A and B, then the quantity
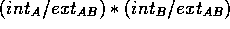
can be calculated, where 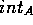 is the number of internal
contacts in A,
is the number of internal
contacts in A, 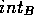 the number of internal contacts in B
and
the number of internal contacts in B
and 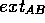 the number of contacts between A and B. This quantity is
referred to as the split value. The split value will
be large if the A and B are distinct
If the two parts are not distinct
(i.e. correlated), then the split value will be small.
the number of contacts between A and B. This quantity is
referred to as the split value. The split value will
be large if the A and B are distinct
If the two parts are not distinct
(i.e. correlated), then the split value will be small.